Usability testing
Usability testing is a technique used in user-centered interaction design to evaluate a product by testing it on users. This can be seen as an irreplaceable usability practice, since it gives direct input on how real users use the system.[1] This is in contrast with usability inspection methods where experts use different methods to evaluate a user interface without involving users.
Usability testing focuses on measuring a human-made product's capacity to meet its intended purpose. Examples of products that commonly benefit from usability testing are foods, consumer products, web sites or web applications, computer interfaces, documents, and devices. Usability testing measures the usability, or ease of use, of a specific object or set of objects, whereas general human-computer interaction studies attempt to formulate universal principles.
Contents |
History of usability testing
Henry Dreyfuss in the late 1940s contracted to design the state rooms for the twin ocean liners "Independence" and "Constitution." He built eight prototype staterooms and installed them in a warehouse. He then brought in a series of travelers to "live" in the rooms for a short time, bringing with them all items they would normally take when cruising. His people were able to discover over time, for example, if there was space for large steamer trunks, if light switches needed to be added beside the beds to prevent injury, etc., before hundreds of state rooms had been built into the ship.[2]
A Xerox Palo Alto Research Center (PARC) employee wrote that PARC used extensive usability testing in creating the Xerox Star, introduced in 1981.[3] Only about 25,000 units were sold, leading many to consider the Xerox Star a commercial failure.
The Inside Intuit book, says (page 22, 1984), "... in the first instance of the Usability Testing that later became standard industry practice, LeFevre recruited people off the streets... and timed their Kwik-Chek (Quicken) usage with a stopwatch. After every test... programmers worked to improve the program."[1]) Scott Cook, Intuit co-founder, said, "... we did usability testing in 1984, five years before anyone else... there's a very big difference between doing it and having marketing people doing it as part of their... design... a very big difference between doing it and having it be the core of what engineers focus on.[4]
Goals of usability testing
Usability testing is a black-box testing technique. The aim is to observe people using the product to discover errors and areas of improvement. Usability testing generally involves measuring how well test subjects respond in four areas: efficiency, accuracy, recall, and emotional response. The results of the first test can be treated as a baseline or control measurement; all subsequent tests can then be compared to the baseline to indicate improvement.
- Performance -- How much time, and how many steps, are required for people to complete basic tasks? (For example, find something to buy, create a new account, and order the item.)
- Accuracy -- How many mistakes did people make? (And were they fatal or recoverable with the right information?)
- Recall -- How much does the person remember afterwards or after periods of non-use?
- Stickiness -- How much time he spends
- Emotional response -- How does the person feel about the tasks completed? Is the person confident, stressed? Would the user recommend this system to a friend?
What usability testing is not
Simply gathering opinions on an object or document is market research or qualitative research rather than usability testing. Usability testing usually involves systematic observation under controlled conditions to determine how well people can use the product.[5] However, often both qualitative and usability testing are used in combination, to better understand users' motivations/perceptions, in addition to their actions.
Rather than showing users a rough draft and asking, "Do you understand this?", usability testing involves watching people trying to use something for its intended purpose. For example, when testing instructions for assembling a toy, the test subjects should be given the instructions and a box of parts and, rather than being asked to comment on the parts and materials, they are asked to put the toy together. Instruction phrasing, illustration quality, and the toy's design all affect the assembly process.
Methods
Setting up a usability test involves carefully creating a scenario, or realistic situation, wherein the person performs a list of tasks using the product being tested while observers watch and take notes. Several other test instruments such as scripted instructions, paper prototypes, and pre- and post-test questionnaires are also used to gather feedback on the product being tested. For example, to test the attachment function of an e-mail program, a scenario would describe a situation where a person needs to send an e-mail attachment, and ask him or her to undertake this task. The aim is to observe how people function in a realistic manner, so that developers can see problem areas, and what people like. Techniques popularly used to gather data during a usability test include think aloud protocol, Co-discovery Learning and eye tracking.
Hallway testing
Hallway testing (or Hall Intercept Testing) is a general methodology of usability testing. Rather than using an in-house, trained group of testers, just five to six random people, indicative of a cross-section of end users, are brought in to test the product, or service. The name of the technique refers to the fact that the testers should be random people who pass by in the hallway.[6]
Hallway testing is particularly effective in the early stages of a new design when the designers are looking for "brick walls," problems so serious that users simply cannot advance. Anyone of normal intelligence other than designers and engineers can be used at this point. (Both designers and engineers immediately turn from being test subjects into being "expert reviewers." They are often too close to the project, so they already know how to accomplish the task, thereby missing ambiguities and false paths.)
Remote Usability Testing
In a scenario where usability evaluators, developers and prospective users are located in different countries and time zones, conducting a traditional lab usability evaluation creates challenges both from the cost and logistical perspectives. These concerns led to research on remote usability evaluation, with the user and the evaluators separated over space and time. Remote testing, which facilitates evaluations being done in the context of the user’s other tasks and technology can be either synchronous or asynchronous. Synchronous usability testing methodologies involve video conferencing or employ remote application sharing tools such as WebEx. The former involves real time one-on-one communication between the evaluator and the user, while the latter involves the evaluator and user working separately.[7]
Asynchronous methodologies include automatic collection of user’s click streams, user logs of critical incidents that occur while interacting with the application and subjective feedback on the interface by users.[8] Similar to an in-lab study, an asynchronous remote usability test is task-based and the platforms allow you to capture clicks and task times. Hence, for many large companies this allows you to understand the WHY behind the visitors' intents when visiting a website or mobile site. Additionally, this style of user testing also provides an opportunity to segment feedback by demographic, attitudinal and behavioural type. The tests are carried out in the user’s own environment (rather than labs) helping further simulate real-life scenario testing. This approach also provides a vehicle to easily solicit feedback from users in remote areas.
Numerous tools are available to address the needs of both these approaches. WebEx and Go-to-meeting are the most commonly used technologies to conduct a synchronous remote usability test.[9] However, synchronous remote testing may lack the immediacy and sense of “presence” desired to support a collaborative testing process. Moreover, managing inter-personal dynamics across cultural and linguistic barriers may require approaches sensitive to the cultures involved. Other disadvantages include having reduced control over the testing environment and the distractions and interruptions experienced by the participants’ in their native environment.[10] One of the newer methods developed for conducting a synchronous remote usability test is by using virtual worlds.[11]
Expert review
Expert review is another general method of usability testing. As the name suggests, this method relies on bringing in experts with experience in the field (possibly from companies that specialize in usability testing) to evaluate the usability of a product.
Automated expert review
Similar to expert reviews, automated expert reviews provide usability testing but through the use of programs given rules for good design and heuristics. Though an automated review might not provide as much detail and insight as reviews from people, they can be finished more quickly and consistently. The idea of creating surrogate users for usability testing is an ambitious direction for the Artificial Intelligence community.
How many users to test?
In the early 1990s, Jakob Nielsen, at that time a researcher at Sun Microsystems, popularized the concept of using numerous small usability tests—typically with only five test subjects each—at various stages of the development process. His argument is that, once it is found that two or three people are totally confused by the home page, little is gained by watching more people suffer through the same flawed design. "Elaborate usability tests are a waste of resources. The best results come from testing no more than five users and running as many small tests as you can afford.".[6] Nielsen subsequently published his research and coined the term heuristic evaluation.
The claim of "Five users is enough" was later described by a mathematical model[12] which states for the proportion of uncovered problems U
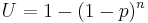
where p is the probability of one subject identifying a specific problem and n the number of subjects (or test sessions). This model shows up as an asymptotic graph towards the number of real existing problems (see figure below).
In later research Nielsen's claim has eagerly been questioned with both empirical evidence[13] and more advanced mathematical models.[14] Two key challenges to this assertion are:
- since usability is related to the specific set of users, such a small sample size is unlikely to be representative of the total population so the data from such a small sample is more likely to reflect the sample group than the population they may represent
- Not every usability problem is equally easy-to-detect. Intractable problems happen to decelerate the overall process. Under these circumstances the progress of the process is much shallower than predicted by the Nielsen/Landauer formula.[15]
It is worth noting that Nielsen does not advocate stopping after a single test with five users; his point is that testing with five users, fixing the problems they uncover, and then testing the revised site with five different users is a better use of limited resources than running a single usability test with 10 users. In practice, the tests are run once or twice per week during the entire development cycle, using three to five test subjects per round, and with the results delivered within 24 hours to the designers. The number of users actually tested over the course of the project can thus easily reach 50 to 100 people.
In the early stage, when users are most likely to immediately encounter problems that stop them in their tracks, almost anyone of normal intelligence can be used as a test subject. In stage two, testers will recruit test subjects across a broad spectrum of abilities. For example, in one study, experienced users showed no problem using any design, from the first to the last, while naive user and self-identified power users both failed repeatedly.[16] Later on, as the design smooths out, users should be recruited from the target population.
When the method is applied to a sufficient number of people over the course of a project, the objections raised above become addressed: The sample size ceases to be small and usability problems that arise with only occasional users are found. The value of the method lies in the fact that specific design problems, once encountered, are never seen again because they are immediately eliminated, while the parts that appear successful are tested over and over. While it's true that the initial problems in the design may be tested by only five users, when the method is properly applied, the parts of the design that worked in that initial test will go on to be tested by 50 to 100 people.
See also
- ISO 9241
- Software testing
- Educational technology
- Universal usability
- Commercial eye tracking
- Don't Make Me Think
- Performance testing
- System Usability Scale (SUS)
- Test method
- Tree testing
- RITE Method
- Component-Based Usability Testing
- Crowdsource testing
References
- ^ Nielsen, J. (1994). Usability Engineering, Academic Press Inc, p 165
- ^ NN/G Usability Week 2011 Conference "Interaction Design" Manual, Bruce Tognazzini, Nielsen Norman Group, 2011
- ^ http://interactions.acm.org/content/XV/baecker.pdf
- ^ http://news.zdnet.co.uk/itmanagement/0,1000000308,2065537,00.htm
- ^ http://jerz.setonhill.edu/design/usability/intro.htm
- ^ a b http://www.useit.com/alertbox/20000319.html
- ^ http://portal.acm.org/citation.cfm?id=1240838&dl=
- ^ http://portal.acm.org/citation.cfm?id=971264
- ^ http://www.boxesandarrows.com/view/remote_online_usability_testing_why_how_and_when_to_use_it
- ^ Dray, Susan; Siegel, David (March 2004). "Remote possibilities?: international usability testing at a distance". Interactions 11 (2): 10–17. doi:10.1145/971258.971264.
- ^ Chalil Madathil, Kapil; Joel S. Greenstein (May 2011). "Synchronous remote usability testing: a new approach facilitated by virtual worlds". Proceedings of the 2011 annual conference on Human factors in computing systems. CHI '11: 2225–2234. doi:portal.acm.org/citation.cfm?doid=1978942.1979267.
- ^ Virzi, R.A., Refining the Test Phase of Usability Evaluation: How Many Subjects is Enough? Human Factors, 1992. 34(4): p. 457-468.
- ^ http://citeseer.ist.psu.edu/spool01testing.html
- ^ Caulton, D.A., Relaxing the homogeneity assumption in usability testing. Behaviour & Information Technology, 2001. 20(1): p. 1-7
- ^ Schmettow, Heterogeneity in the Usability Evaluation Process. In: M. England, D. & Beale, R. (ed.), Proceedings of the HCI 2008, British Computing Society, 2008, 1, 89-98
- ^ Bruce Tognazzini. "Maximizing Windows". http://www.asktog.com/columns/000maxscrns.html.